A custom solution with Python and Pandas for an incremental deployment
This year (2022/10/05) at @DataRelay in Birmingham, I presented my first session on a big screen outside a customer or colleague context. Had a lot of fun doing this. As well as some request for sharing my code.
In this post, I will explain why I created a custom solution and how to use it. All code can be found in my GitHub Repository, linked at the end of the post.
Easiest way to get started is with Visual Studio Code and the Jupyter extension, as well as the Python PYODBC module and the Pandas module.
Why a custom solution
From my point of view, SQL Server Data Tools would be the first place to look for Source Control on a SQL Server project. Unfortunately, this doesn’t work for Synapse Serverless SQL.
To follow DevOps best practices for Source Control and Automated Deployments, I needed a custom solution.
Both Source Control and Deployment solutions are written in python and can be run locally or from an Azure DevOps agent.
High-level Architecture
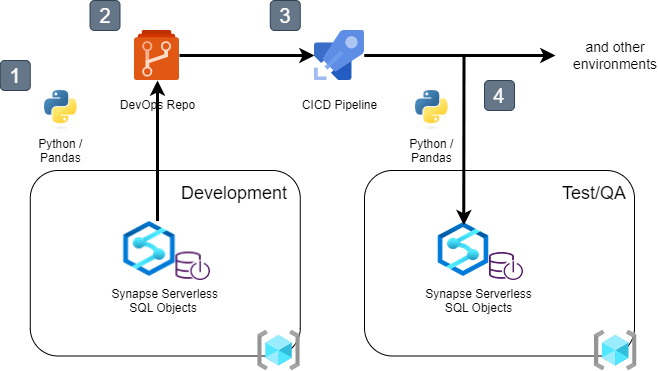
Source Control for Synapse Serverless SQL
The first Jupyther Notebook, ‘01-export-views-to-sql-files.ipynb‘, is a way to add your database objects to a local folder, which you could add to your repository.
Main reason for not using the Synapse Workspace SQL Scripts user interface is the readability of the files in your repository. Apart from the first point, the more scripts stored in the Workspace as Artifacts, significantly slows down the deployment of your workspace.
Simple deployment to Target Serverless SQL pool
The second Notebook ‘02-execute-sql-on-serverless.ipynb‘ looks very similar to the first one. It contains a way to deploy the scripts from your Repository to a target server. All scripts in the specified folder will be executed in alphabetical order.
Please note that you probably need to alter/add some logic to override specific environment references. In example a data lake reference or a database reference.
Incremental deployment with Pandas
The last Notebook ‘03-compare-and-execute-sql-on-serverless.ipynb‘ contains logic for an incremental deployment.
Within the notebook the repository is loaded to a dataframe and the target server is loaded. Next all sql statements are compered to detect actual changes. This includes drops statements for objects that no longer exists in the source.
The created dataframes for comparison and execution can be saved as delimited text files for later reference. If done from an Azure DevOps Pipeline, they can be published as Artifacts.
This script can be converted to a .py file and run from an Azure DevOps agent. The repository contains yaml and PowerShell examples on how to do this.
What’s next?
Since this is a custom solution I will keep on developing new ways to improve the process and code. On top of my wish list is external tables and a fix for failed execution when files/folders in the data lake do not exist.
If you have any feedback and are willing to share, please let me know!

1 thought on “How to CI/CD Synapse Serverless SQL”